Many libraries including the Greenwich Public Library (CT) have oral history collections of residents, famous and not so famous. But as the US population ages, people are starting to wonder if what they’re creating online will survive them.
Libraries have always kept some kind of vertical file for local residents. The DeKalb Public Library (IL) has a file on author Richard Powers, which proved recently valuable when The Echo Maker won the National Book award.
Perhaps it’s time for libraries to run their own blog aggregators, so that the next Richard Powers’ juvenelia can be preserved for posterity. Open source aggregators exist, from Gregarius (PHP) to Planet (Python) to Plagger (Perl).
Dave Winer, popular for an early vision of weblogs, RSS, and podcasting, among other things, wrote in a post entitled Future Archives, “When a scholar dies, he or she leaves behind a life of work, papers, unfinished manuscripts, notebooks, pictures, recordings, and nowadays computers, disks and websites. Their family and university generally don’t know what to do with them, often the problem is given to the libraries.” Winer went on to say, “Our thought is to try to anticipate the problem, while the scholar is alive, and now that our work is largely electronic, to have it future-safe at all times, leave no work for the librarian, let the families and colleagues deal with the death of a relative and colleague at a personal level, and not as a professional problem.”
Amazon’s Simple Storage Service (S3), which offers metered storage on its servers, has been discussed as one possible solution. Other internet service providers have seen this need, and offer their own solutions. Joyent has Strongspace, which promises to give “a secure place to gather, backup and share any type of file.” Dreamhost has Files Forever, which promises to “keep uploaded files private [to use] as a permanent archive.”
Solution within reach
Jon Udell, Microsoft technology evangelist and pioneer of LibraryLookup, has been thinking along the same lines, writing “I have ventured into this confusing landscape because I think that the issues that libraries and academic publishers are wrestling with persistent long-term storage, permanent URLs, reliable citation indexing and analysis are ones that will matter to many businesses and individuals. As we project our corporate, professional, and personal identities onto the web, we’ll start to see that the long-term stability of those projections is valuable and worth paying for.
In Udell’s podcast with Dan Chudnov, librarian and technologist, they discuss possible alternatives. Chudnov went on to post a vision of what a library project dedicated to archiving weblogs would look like from a 2004 conference discussion (see below), since updated to include Atom instead. This service, which mirrors the journal archive service LOCKSS (Lots of Copies Keep Stuff Safe), holds promise for keeping electronic content from falling into a digital black hole.
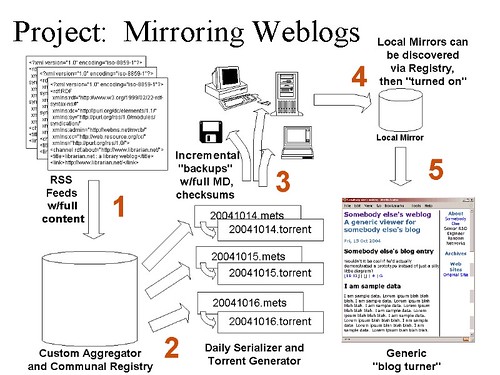
Weblog mirroring system diagram, originally uploaded by dchud.